

Most event organizers treat risk management like insurance paperwork—something you fill out once and hope you never need. Then a vendor ghosts you three days before the conference, or the keynote speaker's flight gets canceled, and suddenly you're scrambling through old emails trying to remember who your backup AV provider was.
After watching hundreds of events navigate everything from minor hiccups to complete operational meltdowns, one thing becomes clear: the difference between a smooth recovery and total chaos isn't luck. It's having a proper event risk framework that connects your risk categories to actual operational triggers and response protocols.
Why Traditional Risk Lists Break Down During Events
Every event planner has seen those generic risk assessment templates. They list "weather disruption" and "technical failure" alongside "reputational damage" like they're all somehow equivalent operational concerns. These frameworks look comprehensive in planning meetings but fall apart the moment something actually goes wrong.
The fundamental problem is that most risk frameworks treat each risk as an isolated incident rather than part of an interconnected operational system. When your registration system crashes, it doesn't just create a "technology risk"—it triggers cascading failures across attendee flow, sponsor visibility metrics, session capacity management, and staff allocation. Your response needs to account for all those connections, not just restart the servers.
What makes this worse is how risks compound during live events. A 30-minute delay in vendor setup becomes a bottleneck at registration, which creates crowd buildup at entrances, which triggers safety concerns, which requires pulling staff from other areas, which leaves gaps in exhibitor support. By noon you're dealing with six interconnected problems that all started with one truck arriving late.
Listing risks in a spreadsheet and assigning probability scores might satisfy board requirements, but it doesn't help your operations team when they're making split-second decisions at 7 AM on event day.
Building a Risk Taxonomy That Maps to Real Operations
An effective event risk framework starts with categorizing risks based on how they actually impact your operations, not what caused them. Instead of organizing by source (weather, vendor, technology), organize by operational impact and response type.
Eliminate event chaos with Festoly.
Manage every aspect of your event seamlessly — from planning to execution.
- Centralized event scheduling
- Real-time attendee tracking
- Vendor & resource coordination
No credit card required
Here's how this looks in practice:
Flow Disruption Risks These affect how people and resources move through your event. Entrance bottlenecks, registration crashes, venue access issues, transportation delays. The key characteristic: they create immediate visible queues and require rapid reallocation of space or staff.
Capacity Constraint Risks These happen when a critical resource becomes unavailable or insufficient. Speaker no-shows, vendor failures, equipment breakdowns, staff shortages. Response always involves either finding alternatives or restructuring the program.
Timeline Cascade Risks These throw off your entire schedule and create downstream impacts. Setup delays, extended sessions, technical troubleshooting that runs long. Response requires communication across multiple teams and often public-facing schedule adjustments.
Compliance & Safety Risks These threaten your ability to legally or safely continue operations. Fire code violations, permit issues, medical emergencies, security threats. Response is usually binary—fix immediately or shut down the affected area.
Financial Exposure Risks These impact your budget or revenue without necessarily affecting immediate operations. Sponsor pullouts, lower attendance, unexpected costs, contractual disputes. Response involves financial controls and stakeholder management.
Visualizing these mappings helps operational teams react faster.
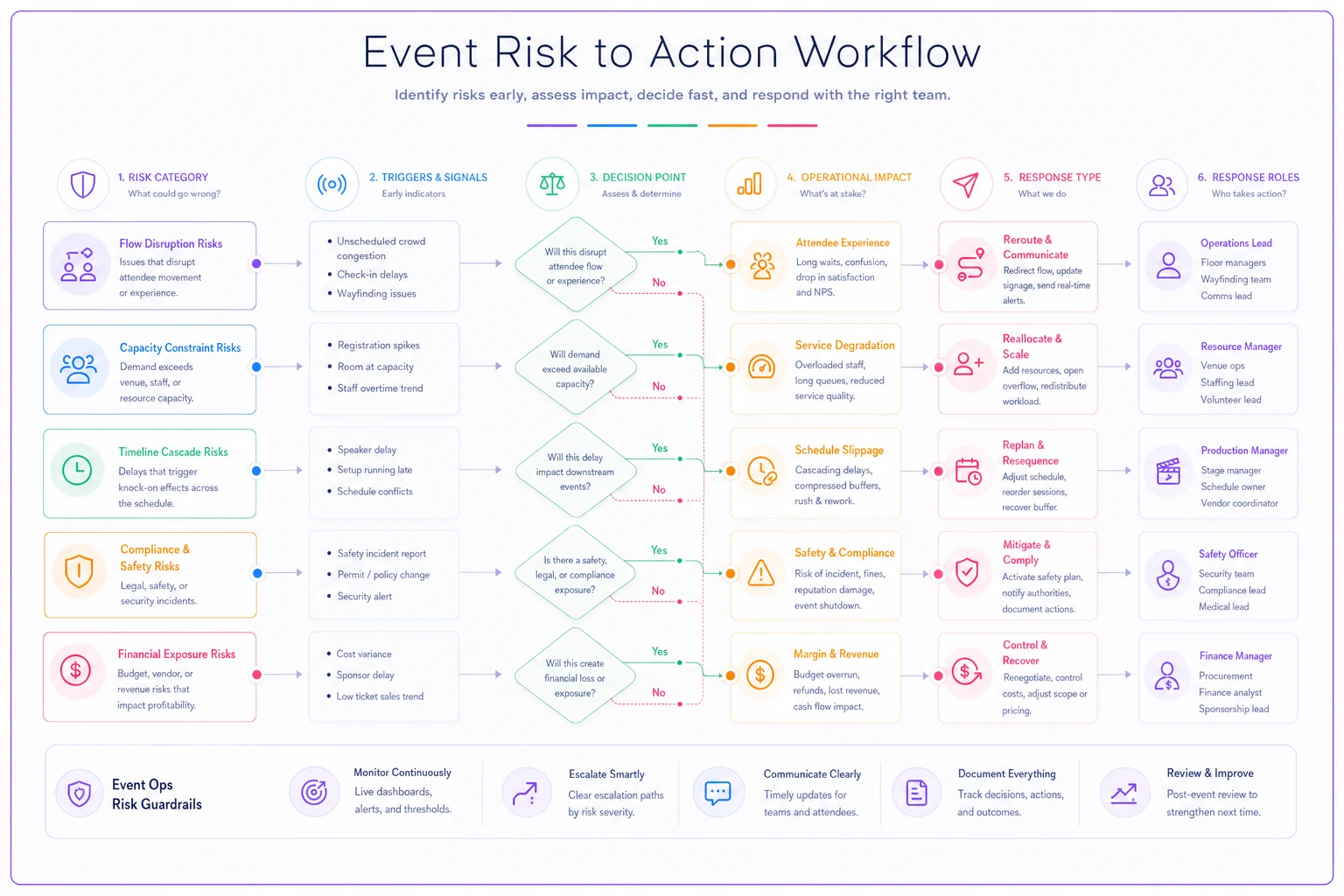
By organizing risks this way, your team immediately knows what type of response is needed without having to analyze the situation from scratch. A registration system crash and a medical emergency at registration might happen in the same location, but they require completely different operational responses.
Mitigation Playbooks That Actually Get Used
The problem with most emergency response plans is they're written like technical manuals—comprehensive but impossible to execute under pressure. Your mitigation playbooks need to function more like operational recipes that someone can follow even when they're stressed and sleep-deprived.
Each playbook should follow this structure:
Immediate Actions (First 5 Minutes)
-
Who makes the call
-
What gets stopped or paused
-
Which backup systems activate
-
Communication triggers (internal only at this stage)
Assessment Phase (5-15 Minutes)
-
Specific data to gather
-
Decision thresholds for escalation
-
Resource availability checks
-
Timeline for resolution decision
Response Execution (15+ Minutes)
-
Step-by-step operational changes
-
Staff redeployment instructions
-
External communication templates
-
Documentation requirements
A vendor no-show playbook, for example, might start with checking whether equipment is already on-site (even without the vendor), then assessing whether internal staff can handle setup, then triggering the backup vendor contact protocol if needed. Each step has a specific owner and a timeline.
Assign a specific owner to each step so there's no ambiguity during activation.
The critical element most frameworks miss: embedding these playbooks into your normal operational handoffs. Your morning briefing checklist should include vendor confirmation status. Your hourly operations report should flag any delays against your cascade thresholds. When mitigation protocols are woven into standard procedures, they actually get followed.
Insurance Levers and Financial Triggers
Insurance is the most misunderstood component of event risk management. Most organizers either over-insure or don't know when or how to actually file a claim. The key is connecting your insurance coverage directly to operational triggers.
Map each coverage type to specific operational scenarios:
| Coverage Type | Operational Trigger | Documentation Needed | Claim Timeline |
|---|---|---|---|
| Cancellation Insurance | Venue unavailable 30+ days out | Force majeure evidence, financial impact | File within 7 days |
| Weather Insurance | Specific conditions met (wind speed, rainfall) | Official weather data, attendance impact | File same day |
| Vendor Default | Contracted vendor fails to appear | Contract, correspondence, replacement costs | Document day-of, file within 30 days |
| Liability Coverage | Attendee injury or property damage | Incident report, witness statements, photos | Immediate documentation |
| Equipment Coverage | Rental equipment damaged or stolen | Police report, rental agreement, photos | Within 24 hours |
The operational trigger is what transforms insurance from paperwork into an actual risk mitigation tool. When your team knows that vendor default coverage requires specific documentation day-of, they'll capture it. When they understand weather triggers, they'll monitor conditions proactively.
Build these requirements into your operational systems. If weather insurance triggers at 40mph winds, your hourly operations report should include wind speed. If vendor default requires proof of attempted contact, your vendor check-in process should generate timestamped records.
Escalation Thresholds Based on Event Scale
Not every risk requires the same level of response, and that calculation changes based on your event's size and complexity. A 50-person workshop can absorb delays that would destroy a 5,000-person conference. Your escalation thresholds need to reflect those operational realities.
Small events under 200 attendees can often handle issues through informal adjustment. If lunch runs 20 minutes late, you shift the afternoon schedule. But once you cross into multi-track, multi-venue operations, that same 20-minute delay requires coordinated communication across dozens of session managers, speakers, and venue coordinators.
Define your escalation triggers based on operational complexity:
Tier 1 Response (Operational team handles)
-
Single venue area affected
-
Less than 15-minute schedule impact
-
Under $1,000 financial exposure
-
No safety concerns
Tier 2 Response (Operations manager involved)
-
Multiple areas affected
-
15-60 minute delays
-
$1,000-5,000 exposure
-
Minor safety considerations
Tier 3 Response (Executive involvement)
-
Entire event impacted
-
Over 60-minute delays
-
Above $5,000 exposure
-
Significant safety risks
These thresholds should decrease as your event grows. A registration delay affecting 50 people might be Tier 1, but the same delay affecting 500 people jumps to Tier 2 because the crowd management implications completely change.
Embedding Triggers in Daily Operations
The most sophisticated risk framework means nothing if your team doesn't know when to activate it. This is where most events fail—they have well-documented crisis management plans that sit unused because nobody recognizes the crisis until it's too late.
The fix is embedding risk triggers directly into your standard operational checkpoints. Your modular operations playbook should include risk indicators at every handoff point.
Morning setup checklist includes:
-
Vendor arrival confirmation (trigger
no-show protocol if missing)
-
Weather check against insurance thresholds
-
Staff attendance versus minimum requirements
-
Equipment functionality verification
Hourly operations rounds include:
-
Queue length checks against capacity triggers
-
Schedule adherence monitoring
-
Incident report review
-
Budget burn rate analysis
Risk monitoring becomes automatic this way. Your team isn't trying to remember to check for problems—they're following their normal routines that happen to include risk triggers.
When triggers fire, the response is equally embedded. If morning vendor confirmation fails, the playbook launches. If queue lengths exceed thresholds, redistribution protocols activate. The framework operates through your normal workflows rather than alongside them.
Technology Failures and Cascade Prevention
Technology risks deserve special attention because they tend to create the fastest cascading failures. When your registration system goes down, you don't just lose check-in capability—you lose attendance tracking, session capacity management, lead retrieval for sponsors, and potentially payment processing.
The key to managing technology risks is understanding your dependency chains. Map out which systems rely on which other systems:
Registration System Dependencies:
-
Badge printing (immediate visible impact)
-
Session scanning (capacity management fails)
-
Sponsor lead retrieval (sponsor satisfaction)
-
Attendance analytics (post-event reporting)
-
Payment processing (on-site revenue)
For each dependency, establish manual fallback procedures and triggering thresholds. If registration is down for 15 minutes, switch to paper lists. If it's down for an hour, implement full manual processing and batch-upload later.
More importantly, isolate systems where possible. Your session scanning shouldn't require real-time registration sync. Sponsor lead retrieval can work offline. Payment processing should have mobile backup options. When systems fail in isolation rather than chains, your response options multiply significantly.
Reputation Management and Communication Protocols
Every operational failure has a communication component, but most event risk frameworks treat it as an afterthought. By the time you're crafting crisis messages, the narrative is already spreading through social media.
Build communication triggers directly into your risk response. Each escalation tier should have predetermined communication protocols:
Tier 1 Communication:
-
Internal team notification only
-
Standard resolution messaging ready
-
No external communication unless asked
Tier 2 Communication:
-
Pre-event
Email to affected attendees
-
During event
Signage and staff briefings
-
Post-event
Follow-up with impacted groups
Tier 3 Communication:
-
Immediate social media acknowledgment
-
Email to all attendees
-
Media statement prepared
-
Board/stakeholder notification
One detail that gets overlooked: your communication triggers should activate before the full resolution is known. Acknowledging an issue quickly with limited information beats perfect communication that comes too late.
Building Your Implementation Timeline
Creating a comprehensive event risk framework doesn't happen overnight, and trying to implement everything at once usually means nothing gets properly adopted. Here's a realistic rollout:
Phase 1 (Before your next event): Start with your highest-probability, highest-impact risks—usually vendor failures, weather issues, and registration problems. Create basic playbooks for these three. Include them in your next event's operational briefing.
Phase 2 (Next 2-3 events): Expand your taxonomy to cover all major risk categories. Build escalation thresholds based on your actual event sizes. Start embedding triggers in your standard operating procedures.
Phase 3 (Within 6 months): Complete integration with insurance coverage mapping. Develop full communication protocols. Train your entire team on the framework. Begin capturing metrics on trigger activation and response effectiveness.
Phase 4 (Ongoing): Refine thresholds based on actual incidents. Expand playbooks based on new scenarios. Integrate learnings from each event into framework updates.
Software Infrastructure for Risk Management
You can manage basic risk frameworks through spreadsheets and printed playbooks, but the real-time nature of event operations makes manual tracking increasingly difficult as your events grow. Modern event management platforms now include risk monitoring capabilities that automatically track triggers and alert the right team members without someone having to babysit a spreadsheet.
The key functionality to look for includes automated vendor confirmation workflows that trigger escalation when vendors don't respond, real-time dashboard monitoring that flags when operational metrics exceed thresholds, and integrated communication tools that execute your notification protocols automatically. These platforms turn your risk framework from a static document into a living operational system.
Some platforms now incorporate pattern recognition to flag emerging risks before they trigger formal thresholds. If registration processing time gradually increases, the system can alert you to investigate before it becomes a visible queue problem. That predictive capability is particularly valuable for multi-day events where patterns from day one can prevent problems on day two.
Integration between risk management and your other operational tools matters just as much. When a vendor contract milestone is missed, it should automatically trigger both the operational response and financial controls. When crowd density exceeds safety thresholds, it should simultaneously alert security, adjust digital signage, and pause marketing pushes that drive more people to that area.
Learning from Near-Misses
The most valuable moments for improving your event risk framework aren't the actual failures—they're the near-misses that almost became failures. These situations reveal where your triggers are too sensitive or not sensitive enough.
After each event, conduct a near-miss review alongside your standard debrief:
-
Which playbooks were activated?
-
Which escalation triggers fired?
-
What almost went wrong but didn't?
-
Where did manual intervention prevent automated triggers?
A registration system that stayed up but ran slowly might not trigger your current framework. But if staff had to constantly restart tablets, you need earlier warning indicators. A vendor who showed up late but still completed setup might not activate protocols, but if it created downstream stress, your triggers need adjustment.
Document near-misses with the same rigor as actual incidents. They're your early warning system for framework refinement.
Scaling Considerations
As your events grow, your risk framework needs fundamental restructuring, not just parameter adjustments. What works for standalone events breaks down when you're running multiple simultaneous events or year-round programming.
Multi-event operations require centralized risk monitoring with local response authority. You can't have every vendor delay escalating to the same operations manager when you're running five events across different cities. Build regional or event-specific response hierarchies while maintaining central framework consistency.
The threshold math also changes completely. A $5,000 financial exposure might be Tier 3 for a single event but becomes routine variance when you're managing dozens of events monthly. Percentage-based thresholds work better than absolute numbers at scale.
Most importantly, your framework needs to account for resource competition. When multiple events face simultaneous risks, who gets the backup equipment? Which event can sacrifice staff to support another? These allocation decisions need predetermined protocols, not real-time negotiation.
Making It Stick
The best event risk framework is worthless if your team doesn't use it consistently. Implementation success depends more on operational integration than framework sophistication.
Start with the basics and build complexity gradually. Make risk triggers part of existing workflows rather than additional tasks. Use your actual decision trees and operational data to set realistic thresholds.
Train your team on the framework during calm periods, not crisis moments. Run tabletop exercises using real scenarios from past events. Update the framework based on actual incidents, not theoretical risks.
Your event risk framework isn't about preventing all problems—that's impossible in live event operations. It's about ensuring that when problems occur, your team knows exactly how to respond, your stakeholders stay informed, and your attendees still have a successful experience despite the chaos. The difference between events that handle disruption gracefully and those that descend into full meltdown isn't luck or even experience. It's having systematic operational protocols that activate when specific conditions are met—not perfect events, but resilient ones that bend without breaking.
Ready to elevate your event management?
Join 5,000+ event organizers using Festoly to save time, improve coordination, and deliver memorable experiences.


